1.Writable简单介绍
在前面的博客中,经常出现IntWritable,ByteWritable.....光从字面上,就可以看出,给人的感觉是基本数据类型 和 序列化!在Hadoop中自带的org.apache.hadoop.io包中有广泛的Writable类可供选择。它们的层次结构如下图所示:
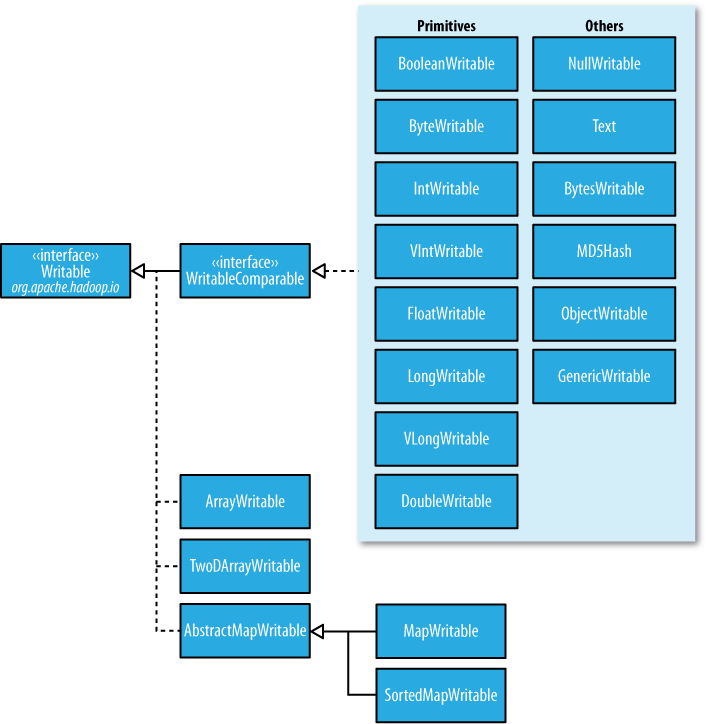
Writable类对Java基本类型提供封装,short 和 char除外(可以存储在IntWritable中)。所有的封装包包含get() 和 set() 方法用于读取或者设置封装的值。如下表所示,Java基本类型的Writable类:
| Java 基本数据类型 | Writable实现 | 序列化大小(字节) |
| boolean | BooleanWritable | 1 |
| byte | ByteWritable | 1 |
| int
| IntWritable VIntWritable | 4 1~5 |
| float | FloatWritable | 4 |
| long
| LongWritable VLongWritable | 8 1~9 |
| double | DoubleWritable | 8 |
2.IntWritable 和 VIntWritable
如上表所示,这两个的区别,很明显,序列化的大小,IntWriable是固定的4个字节,而VintWritable是1~5个字节,是可以变化的!这两个分别在什么场合用?如果需要编码的数值在-127~127之间,变长格式就只用一个字节进行编码;否则,使用一个字节来表示数值的正负和后跟多少个字节。
相比与定长格式,变长格式有什么优点:
(1).定长格式适合对整个值域空间中分布均匀的数值进行编码,大多数数值变量的分布都不均匀,而且变长格式 一般更节省空间。
(2).还有,就是变长格式的VIntWritable和VLlongWritable可以转换,因为他们的编码实际上一致!选择变长格式,更有增长空间。
通过上面,可以知道,变长格式的范围是1~5个字节,那么什么时候是5个字节,什么时候又是3个字节呢?
| 整数的范围 | 序列化字节的大小(字节) |
| -127~127 (-2^7 - 1 ~ 2^7 -1 ) | 1 |
| -256(2的8次方)~ -128 或者 128~255 | 2 |
| -65536(2的16次方)~ -257 或者 256~65535 | 3 |
| -16777216(2的24次方) ~ -65537 或者 65536 ~ 16777215 | 4 |
| -2147483648(2的31次方) ~ -16777217 或者 16777216 ~ 2147483647 | 5 |
问题:
《Hadoop权威指南》上说,需要编码的数值如果相当小(在-127和127之间,包括-127和127),变长格式就只用一个字节进行编码!理论上,我也认为是正确的,但是,我用代码测试了以下,发现-127~-113之间,占用的是2个字节。如下面的例子以及运行结果:
Example:
1 package cn.roboson.writable; 2 3 import java.io.ByteArrayInputStream; 4 import java.io.ByteArrayOutputStream; 5 import java.io.DataInputStream; 6 import java.io.DataOutputStream; 7 import java.io.IOException; 8 9 import org.apache.hadoop.io.IntWritable;10 import org.apache.hadoop.io.VIntWritable;11 import org.apache.hadoop.io.Writable;12 /**13 * 这个例子,主要是为了区分定长和变长,还有就是变长的范围14 * 1.先定义两个IntWritable15 * 2.分别序列化这两个类16 * 3.比较序列化后字节大小17 * @author roboson18 *19 */20 21 public class IntWritableTest {22 23 public static void main(String[] args) throws IOException {24 25 //定义两个比较小的IntWritable,序列化后1个字节的临界点,《Hadoop权威指南》中所说的是-127~127,但是,我发现只能是-112~12726 //超过-112后,就成为2个字节了27 IntWritable writable = new IntWritable(127);28 VIntWritable vwritable = new VIntWritable(-112);29 show(writable,vwritable);30 31 //验证不是从-127~127 32 writable.set(-113);33 vwritable.set(-113);34 show(writable,vwritable);35 36 //序列化后两个字节大小的范围 -256(2的8次方)~ -128 或者 128~255 37 writable.set(-256);38 vwritable.set(-256);39 show(writable,vwritable);40 41 //序列化后3个字节大小的范围 -65536(2的16次方)~ -257 或者 256~6553542 writable.set(-65536);43 vwritable.set(-65536);44 show(writable,vwritable);45 46 //序列化后4个字节大小的范围 -16777216(2的24次方) ~ -65537 或者 65536 ~ 1677721547 writable.set(-16777216);48 vwritable.set(-16777216);49 show(writable,vwritable);50 51 //序列化后4个字节大小的范围 -2147483648(2的31次方) ~ -16777217 或者 16777216 ~ 214748364752 writable.set(-2147483648);53 vwritable.set(-2147483648);54 show(writable,vwritable);55 }56 57 public static byte[] serizlize(Writable writable) throws IOException{58 59 //创建一个输出字节流对象60 ByteArrayOutputStream out = new ByteArrayOutputStream();61 DataOutputStream dataout = new DataOutputStream(out);62 63 //将结构化数据的对象writable写入到输出字节流。64 writable.write(dataout);65 return out.toByteArray();66 }67 68 public static byte[] deserizlize(Writable writable,byte[] bytes) throws IOException{69 70 //创建一个输入字节流对象,将字节数组中的数据,写入到输入流中71 ByteArrayInputStream in = new ByteArrayInputStream(bytes);72 DataInputStream datain = new DataInputStream(in);73 74 //将输入流中的字节流数据反序列化75 writable.readFields(datain);76 return bytes;77 78 }79 80 public static void show(Writable writable,Writable vwritable) throws IOException{81 //对上面两个进行序列化82 byte[] writablebyte = serizlize(writable);83 byte[] vwritablebyte = serizlize(vwritable);84 85 //分别输出字节大小86 System.out.println("定长格式"+writable+"序列化后字节长大小:"+writablebyte.length );87 System.out.println("变长格式"+vwritable+"序列化后字节长大小:"+vwritablebyte.length );88 }89 }
运行结果:

先到这,后面的数据类型,下次继续